昨天,我們完成了 Sprint 4 的需求與 Backlogs,實現了資料庫的儲存與顏色群組的選擇。今天,就讓我們開啟在鐵人賽裡的最後一期 Sprint,一起來優化與解決問題,並將環境部署到 Azure 雲端上。
Sprint 5 的目標是處理環境的問題,在前一個 Sprint,我們完成了 DB 的搭建,然而 DB 是建構在 SIT 上面,等於是整合測試與開發工用一個 DB,這其中各有優缺點,好處是開發人員可以共用 DB 的資料,便於溝通與測試;然而這也會讓 application.properties 中對應的 url 無法更改,當我們想要更動的時候,只能重新打包 Image、另外參數的機敏資訊 (如 password) 以明文顯示,會提升使用上的風險。
因此,我們可以將參數抽象出來,並在 Container 要執行時,才將參數以環境變數的方式傳入內部,另外,也能夠搭配加密,來隱藏參數。
再來,我們目前可執行的環境僅為內網的 SIT 機 (192.168.1.188),若要讓別人使用,則需要將 IP 暴露出來,這時就能夠有雲端與地端自有伺服器的選擇,這次,讓我們先將 Container 部署在 Azure VM 上面。
在 application.properties 內,我們能夠依照環境撰寫多支 properties,並以 profile 分別,其命名方法為:
application-.properties
這裡我們在 cct-java 專案的 resourcess 內創建一個新的檔案,名為 application-local.properties,顧名思義,這一個 properties 適用於本地開發,我們能可以在本機的 sql server 內創建相同的 CCT_DB,並建立使用者,再將本地的 sql server 寫入 properties 內。
#application-local.properties
spring.datasource.url=jdbc:sqlserver://localhost:1433;DatabaseName=CCT_DB
spring.datasource.username=cct-user
spring.datasource.password=cct-user-passwd
在啟動 Eclipse 時,我們能夠對專案選擇 Run As => Run Configuration,並在 Profile 內輸入 local,此時 Eclipse 就會啟用 local 的 properties 配置。
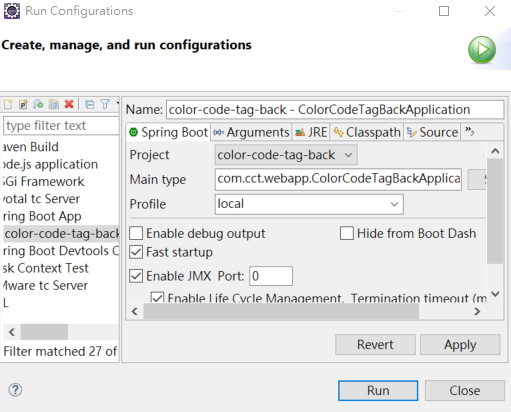
而針對正式的 application.properties,我們則可以將內部的參數抽離(或說將其抽象),並在 Container 啟動時才以指令放入。
#application.properties
spring.datasource.url=${SQL_SERVER_URL_CCT_DB}
spring.datasource.username=${SQL_SERVER_USR_CCT_DB}
spring.datasource.password=${SQL_SERVER_PASSWD_CCT_DB}
而在 container 啟動時,我們在將參數以環境變數的方式丟入。
sudo docker run \
-e SQL_SERVER_URL_CCT_DB=jdbc:sqlserver://192.168.1.188:1433;DatabaseName=CCT_DB \
-e SQL_SERVER_USR_CCT_DB=username \
-e SQL_SERVER_PASSWD_CCT_DB \
-p 8081:8081 \
-d image name
這裡我們就能將帳密寫於腳本並加密,同時在不同環境下,連線到不同的資料庫了。
關於於雲端的部署,由於 Harbor 建構在地端,在外部的網路會無法進入內網,故今天就模擬一下如果 Harbor 建構在雲端或可被外網聯繫的情況下,如何串接 Pipeline。
關於伺服器的選擇,我們能夠使用自行架設的機器建立私有雲 (On-Premises),也能夠向 Azure、AWS、GCP 等雲端商家租用方案;使用自行架設的好處是能夠將所有的資料與保存在公司企業的機房內,目前台灣的一些金融法規會限制不可將資料儲存在台灣之外,也是部分公司架設私有雲的主因;另外自行架設也需要專業的維運團隊管理。
而使用雲端的服務,則可以依照託管程度的不同,又分為 IaaS、SaaS、PaaS,這裡簡單介紹一下:
當然,想要有越高的自由度,則需要自行管理的內容就越多,而需要負擔的責任也就越大:
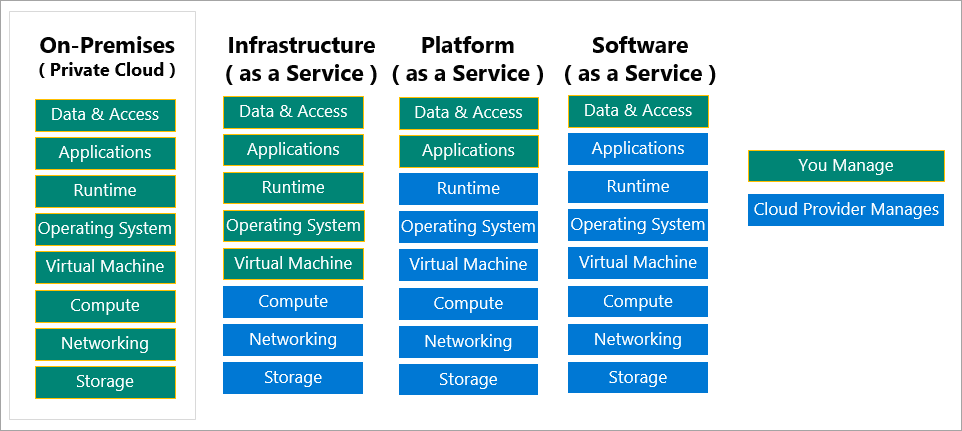
簡單的介紹了幾個服務類型後,基於我們要同時運作前後端與 DB 三個 Container,我們就來使用 Azure VM 這個 IaaS 服務;而不管使用任何雲端服務之前,我們都一定要去看看定價,Azure 為他們的服務提供了一個定價計算機的功能,能讓我們在搭建之前先計算會花費的價錢。
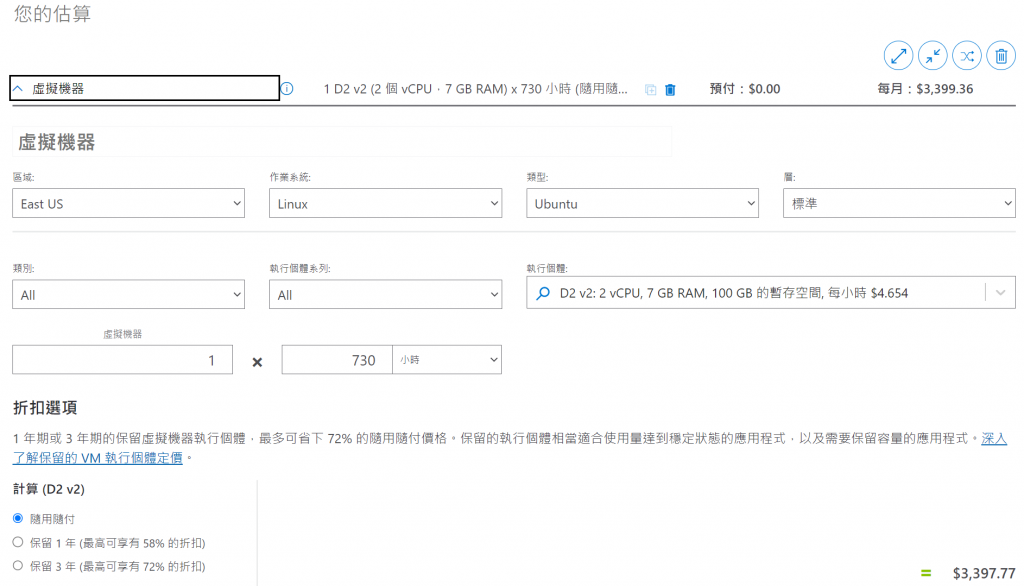
(恩...我的荷包君說拍完影片還是果斷關掉吧)
接著,我們就來搭建 Azure VM 吧!這裡我將會使用隨用隨付 (Pay as you go) 方案,並在測試完成後關閉。首先,讓我們一起登入 Azure Protal。另外也推薦想了解 Azure 雲端的夥伴考取 AZ-900 的證照,微軟會不定時發佈線上課程,若完整參與則可獲得免費的考試機會。
登入之後,我們要先建立一個資源群組 (Resource Group),資源群組是免費的,他的設計目的是將相同產品生命週期的服務放置再一起,能夠共同管理。我們點選 Resource Group 的 logo,並點選 Create,接著為 Resource Group 命名,並選擇區域。
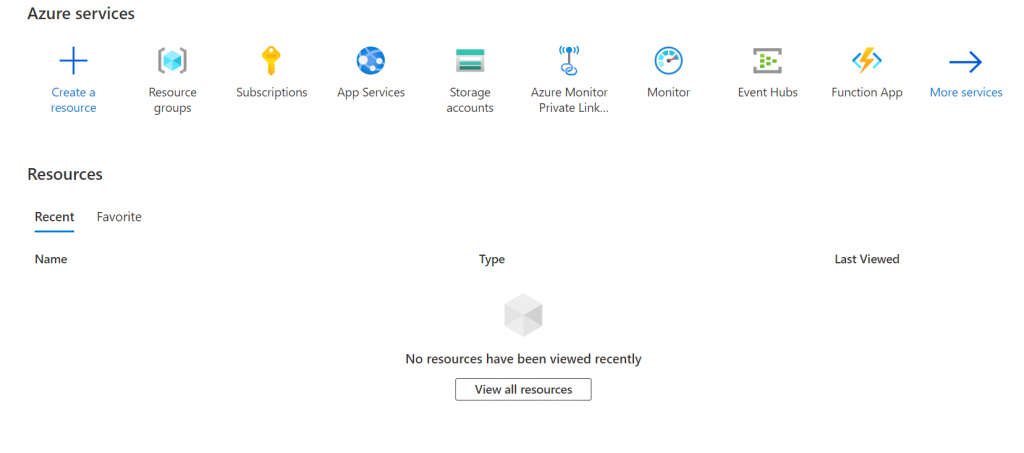
建立好後,我們可以直接在上方的欄位搜尋虛擬機器 (Virtual machines),並點選 Create,接著選擇資源群組、並為 VM 命名,以及選擇方案;這裡我們選用 password 的方式管理。
建立好後,我們就能在虛擬機器的主頁面看到 Public IP address,就能使用 Putty 遠端連線進去啦,後續的部分我們參考先前的建構流程,為 Ubuntu 安裝 Docker。
後續只要依照前幾天的流程完成以下內容(詳細則不贅述):
這裡我們分析一下,我們將昨天為止創建的 Webhook 觸發改動成 Developer 分支,當 Developer 更新時,我們則編譯建構 Image 並推送到 Harbor,並拉取後部署。此時我們就能夠先在 SIT 測試,確認沒問題後,我們才繼續向下合併分支,直至 master 被觸發,僅執行拉取與部署,不再次執行打包。
此時我們終極的 Pipeline 與環境對應則長成這樣:
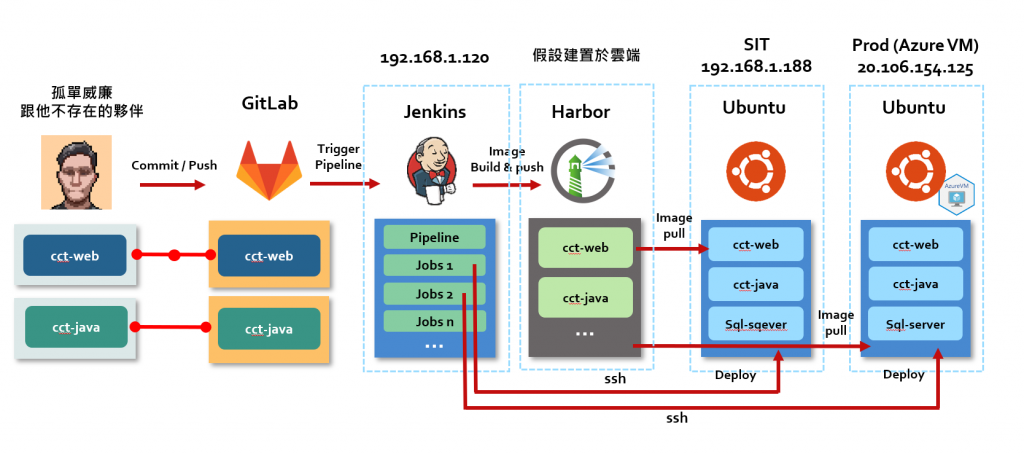
比較可惜是這次 Harbor 與 Jenkins 建於地端,想要觸發 CD 很容易受到限制 (如 Gtilab webhook 等),等明年撥一筆預算架設 Harbor 30 天好了
今天,我們把 Properties 抽離後,將 Production 環境建構在 Azure VM 上面,並且模擬將其納入了 Pipeline 的範圍內,到此,我們算完成了這次鐵人賽的初衷:
以敏捷的精神,從零開始打造一個簡單的前後端分離網站,並容器化後自動部署於 Linux 伺服器上,再逐一迭代完善功能
而在雲端上其實有非常多的方案能夠達成我們今天的目的,如使用 Azure App Service 部署前後端,搭配 Azure SQL Server 儲存資料,希望未來有機會能跟大家分享不同的部署方式。
明天,終於可以寫一個感人的大結局了。

